

The State of AI Generated Fake Videos
I'm not sure if humanity is ready for this.




In this past issue, I covered the subject of AI-powered deep fakes. I also covered the announcement of Sora AI, a breakthrough video generation model by OpenAI that put the world into excitement and worry at the same time.
As we head toward the election in the US, I would like to cover the progress and the current state of AI generated videos.
After nearly five months since the initial announcement of Sora AI, OpenAI is yet to release the model to the general public. OpenAI themselves acknowledged the concerns involving the possibility of the model being used to spread disinformation. They were also honest enough to share a few examples where the model doesn’t work as expected.
The following illustrates a limitation of Sora AI. It may be able to handle a single fox, but generating multiple foxes in overlapping action results in a fever dream.
It was expected that Sora AI would take its time to address the concerns. Meanwhile, we have new competing AI video generation models in the market that seemingly approach the qualities shown in the Sora AI examples. I will examine them in this issue.
But first of all, let me cover the technology that has a higher chance of misuse.
Have Anyone Say Anything
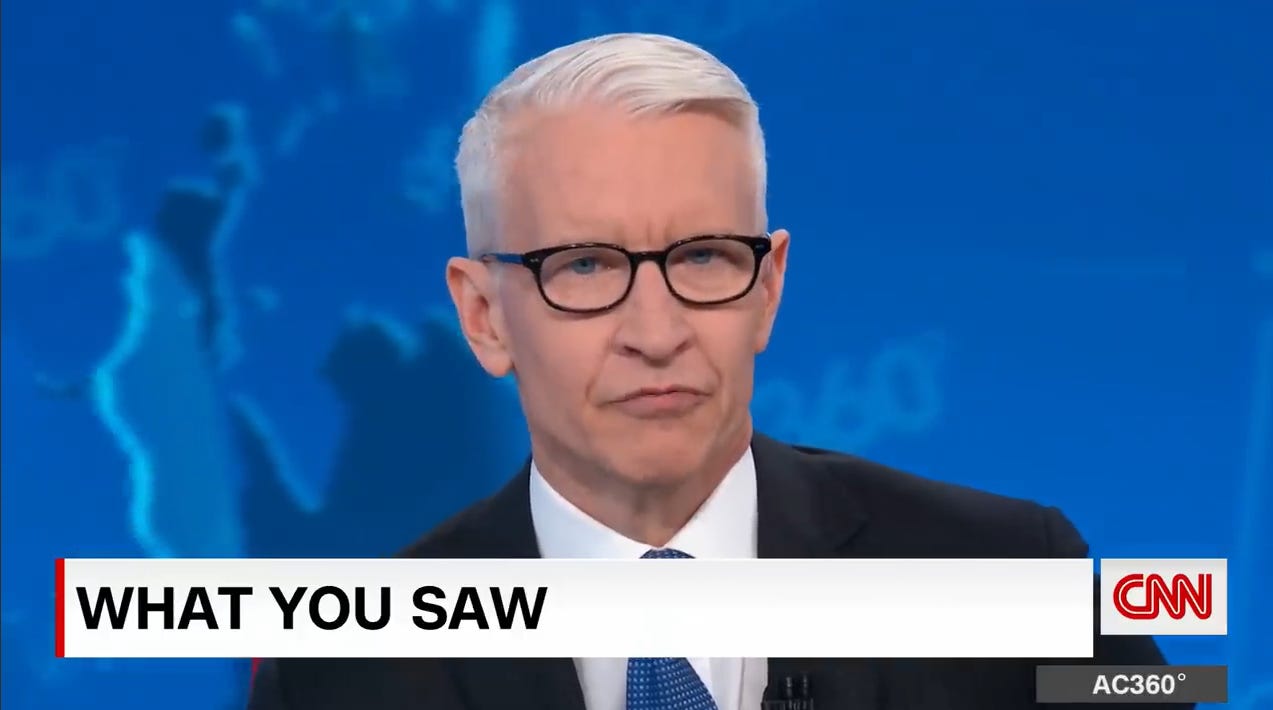
Here I will share an example created using the latest model offered by Sync Labs, one of the leaders in the AI “lip-syncing” technology. I created a fake voice sample of Anderson Cooper using Eleven Labs, and took a real-life example of Anderson Cooper speaking to the camera. Then I used Sync Labs’ latest model to change the lips in the video.
Here is the original video:
Here is the video lip-synced to a synthesized voice sample.
Video from Single Face Image
What if you want to create a lip-synced video, but you have just one single image?
Currently, Hedra AI tackles this challenge better than the alternatives. You just provide a headshot picture, and it will animate the character with plausible head and lip movements. This is particularly useful if you want to animate synthethic images and photographs.
I was impressed that Hedra AI comes with a “safety” feature that checks to see if the picture you upload depicts a celebrity. For that reason, Hedra rejected my attempt to use a picture of Anderson Cooper. To get around the censorship, I generated an image of Anderson Cooper’s long-lost cousin to use with Hedra. Here is the static image.

Here is the video result.
The result is not perfect. You can see Hedra has a slight problem handling a character with eyeglasses. However, if you showed this video to an average person without informing that the video is AI-generated, they may not even notice.
Currently, Hedra AI doesn’t seem to offer an option to create videos in a landscape format. It would be a significant limitation if you are trying to create an AI film. It would be less of a problem if you are trying to use it for social media content generation.
Video From Single Face Image: Using a "Driving Video”
If you are willing to do a little bit of acting yourself, an open-source model called LivePortrait offers a terrific alternative to Hedra AI. The model was developed in China, but is available on its HuggingFace demo page:
To demonstrate how this works, here is the original image:
Here is the “Driving Video.” (From the LivePortrait demo page.)
Here is the end result. My apology to Anderson Cooper.
Does it work with cartoon/anime/comic book images? Yes, up to a certain degree. Here is Naruto, a popular anime character. DC/Marvel style images also work.
The above video probably represents the limit of the model for now. LivePortrait failed to process Homer Simpson and Sailor Moon. They are very stylized and deformed compared to real life faces, so it’s understandable a general-purpose AI model can’t handle them.
Luma AI and Runway Gen-3: Sora AI Competitors?
As OpenAI is taking its time cooking SoraAI before its release, there are two comparable tools available to the general Western public as of now. The first one is Luma Labs Dream Machine and can be accessed here for free.
Dream Machine offers options for text-to-video and image-to-video. Here is a Luma example using text-to-video.
Runway’s Gen-3 Alpha is currently available to the paying customers of Runway’s apps. As the name says, the generator is in Alpha stage and is missing some key features. The most notable missing feature is the “image-to-text” feature available on Runway’s Gen-2 video generator. This current omission limits the utility of the model. On the other hand, the model offers up to 10 seconds of video generation using single prompt, and I found it generally superior to Luma Labs at least in terms of understanding the prompt.
Here is a pretty good example generated using Runway’s Gen-3 Alpha. The video looks fine, but if you look at it carefully, you can make out some minor inconsistencies with background characters.
The following example looks beautiful until. . . the telltale AI-deformed fingers show up.
Let’s look at a worse example. This video features unmistakably misshapen limbs. Both Luma Labs and Gen-3 Alpha have problems with dynamic actions as seen here.
Kling: A Challenger from across the Ocean?
Earlier, I mentioned that there are two comparable models available to the general public in the West. KuaiShou, a Chinese company, offers another frontier video generation AI model named Kling. Unfortunately, it’s only officially available in China. You need a Chinese mobile number in order to access the app. Some Westerners have gained access to the app using online workarounds and ChatGPT translations. The results seem impressive and at least match the results offered by the currently available Western models.
Brave New Imaginary World
When OpenAI first introduced Sora AI, Tyler Perry announced he is putting $800 million film studio expansion on hold. Understandably, he wasn’t sure if the AI technology will soon make the traditional way of film making obsolete.
Clearly, we are not at that stage where AI can completely replace a film studio for feature length movies. However, we are at the stage where one can generate short clips for misinformation or creative projects of a limited scopes. We are entering uncharted territories. I hope to cover more practical use examples in a future issue.