
Making AI useful: Using ChatGPT Vision to Browse Webpages.




Each time OpenAI had a major announcement, it astonished the world. It was no exception when OpenAI introduced ChatGPT4-V with its vision capability. Now with the ability to “see,” some people expected ChatGPT will be ready to interact with the world.
In this article, we will try to combine ChatGPT’s vision capabilities with web scraping/automation. As we do, we will examine its strength and limitations.
First of all, the framework we are going to use is called Puppeteer, or more accurately, its Python implementation—Pyppeteer. Even without any AI, you can achieve impressive feats using this framework. I was able to write Python codes to open my bank’s homepage, fill out my username and password, then CLICK the Login button. Of course, I had to specify exactly what to fill out where, then specify which UI element to click to proceed.

Next, we come to this Great Wall enacted to keep the non-human barbarians out. Can the Python code pass this barrier?
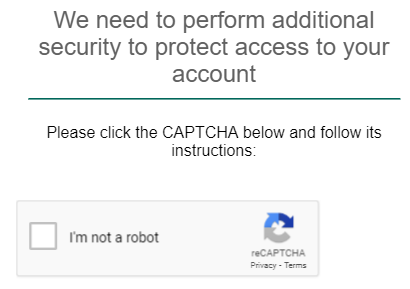
YES!
As long as I tell the code where on the screen to click, it can actually click on “I am not a robot.” and pretend to be human!
But then, we come to an even greater obstacle.
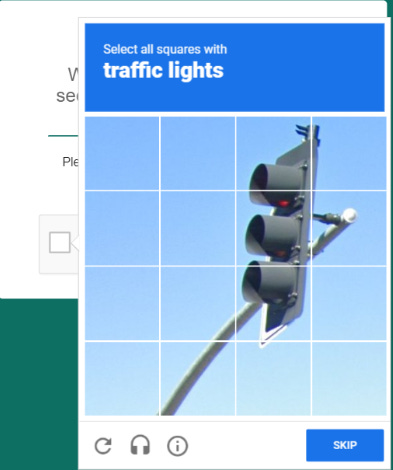
Out of curiosity, I took the screenshot of the grid image to ChatGPT to see if ChatGPT can correctly process this. The result was . . . a spectacular failure.

To be fair, as of now the real way to solve this problem would be to slice the image into 16 squares and analyze them individually. This article discusses this approach in a more technical detail. But even the author of the article admits that this method will not always work.
Strengths and limitations of ChatGPT with Vision
Here is what I found about ChatGPT with Vision: In general, ChatGPT with Vision excels at reading text, understanding the hierarchy of textual elements, and grasping the general contents. However, it fails at obtaining the geometrical relations and coordinate information out of the image. Thus, if you feed the screenshot of the “I am not a robot” page, ChatGPT can’t tell you where the checkbox is. (You can train a custom machine vision model to do this job, but that’s another subject.)
Using ChatGPT to Navigate DYNAMIC Websites
The above experiment with my bank’s homepage worked (until we encountered the image squares) because I knew the exact layout of the starting page. But what about unfamiliar webpages and dynamic web pages where the contents constantly change?
Because of the limitations explained in the previous section, currently you can’t use ChatGPT’s vision API itself to locate the coordinates of the buttons on a webpage and interact with them. But given its ability to read text proficiently, it can work in tandem with Puppeteer to identify links and buttons.
I wrote Python codes to use Puppeteer to navigate to a news site, and take a screenshot. Example code like the following is all you need to automatically navigate to a web page and take a full-screen image.
from pyppeteer import launch
browser = await launch({"headless": False, "args": ["--start-maximized"]})
# create a new page
page = await browser.newPage()
# set page viewport to the largest size
await page.setViewport({"width": 1600, "height": 900})
# navigate to the page (newspage_url)
await page.goto(newspage_url)
# give the page enough time to load
await page.waitFor(5000)
await page.screenshot({"path": "screenshot.png",'fullPage': True})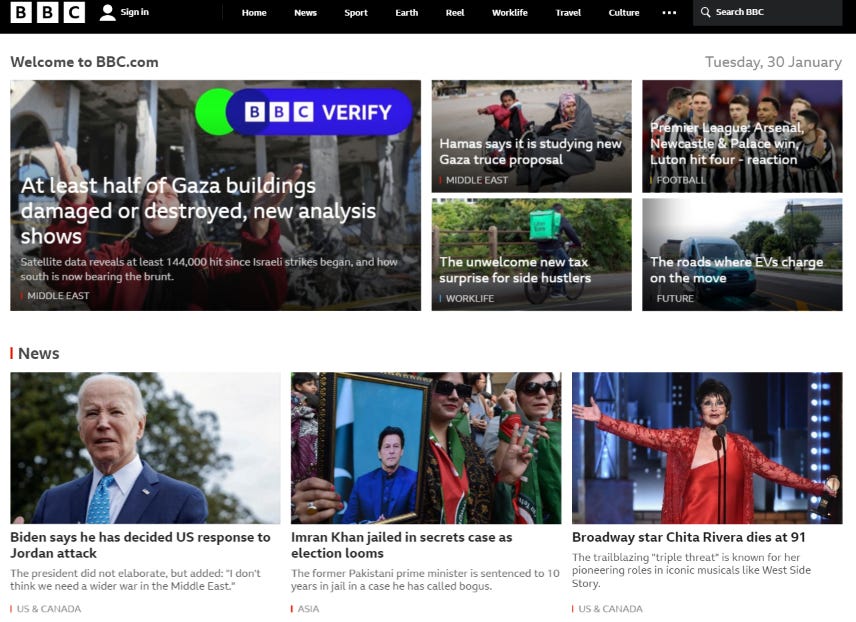
Then, the screenshot was fed to the ChatGPT vision API. ChatGPT was told to look at the news page screenshot and identify the main headline and the rest of news titles.
model = OpenAI()
#input: prompt, b64_image
response = model.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "system",
"content": "Your job is to answer the user's question based on the given screenshot of a website. Answer the user as an assistant.",
},
{"role": "user", "content": prompt},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": f"data:image/jpeg;base64,{b64_image}",
},
{
"type": "text",
"text": prompt,
}
]
}
],
)ChatGPT with Vision does a very good job understanding the hierarchy of the texts on the screenshot image and can identify the main headline and other article titles.
Once we have identified the text for the news links, then we can use this information to locate the link to click. Puppeteer’s API lets you find a link (or a button) containing certain texts. Once the link is located, then Puppeteer can automatically “click” on it to navigate to a new page.
In my code, I used the above process to have ChatGPT identify the main article, then used Puppeteer to automatically navigate to it, and finally had ChatGPT read and summarize the main article.
While this process is far from perfect, the fact that ChatGPT can be used to parse and navigate DYNAMIC pages opens many possibilities. It can be set up to automatically find login links, submit links, form inputs, links to download tax forms and so on.
In theory, it would be possible to construct an application that goes to unfamiliar websites and make semi-intelligent interactions, including booking reservations, writing to the customer service, scraping financial information and so on.
What are some drawbacks? ChatGPT with Vision is rather slow and is not suitable for applications where users expect instant results. Thus, it’s not a good fit for so-called “industrial scale web-scraping” either. I also found that ChatGPT can be confused when viewing article pages with a lot of pictures and ads. In those cases, a more traditional method of text scraping works better.
Now that ChatGPT and AI models can “see,” it would be interesting to see how they can actively interact with the world going forward. As of now this method of web crawling is not robust, but when the vision models improve with more accurate understanding of geometry, it will open up a lot more possibilities. It may even be able to understand the grid puzzle and pick out correct squares.