
How to train your own custom GPT Bot

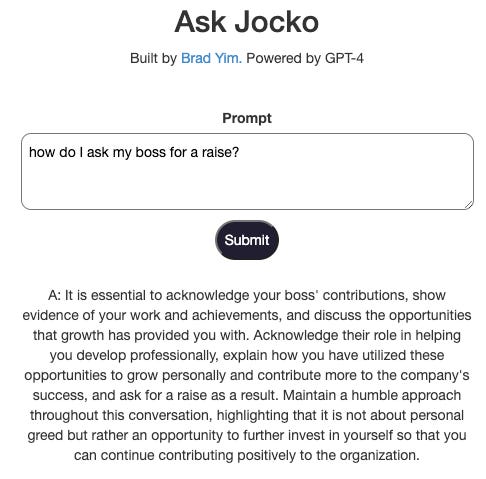
Here my goal was to create a unique chatbot, one that's specifically programmed to reflect Jocko's life philosophy. Imagine having a personal Jocko advisor at your fingertips! Whenever you find yourself pondering, "What would Jocko do?" you'll be able to consult this chatbot for insightful advice.
Who is Jocko you ask? Jocko Willink is an American author, podcaster and retired US Navy officer whose book Extreme Ownership has had an immense impact on my life.
Here is how I went about building the “ChatJocko” ( Basically, the process follows what’s documented here Fine-tuning - OpenAI API ):
BTW, what I’m doing here is called “fine-tuning.” Fine-tuning in AI is like studying for a specific subject after you've learned general knowledge. Think of what I'm doing here as giving our AI a 'specialized education.'
The baseline AI, known as GPT (from OpenAI), has already gained a wealth of general knowledge from a vast amount of data. Now, I'm taking it a step further — I'm immersing it in Jocko's writings, helping it to understand and emulate his style. It's a bit like sending GPT to a masterclass with Jocko himself!

As described in the link above, OpenAI provides API that lets you create your own custom “finetuned” models.
The toughest part is getting the training data ready.
This data should be specific to the kind of responses you want from the bot. Each piece of this data should look like this:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}You might think of these as pairs of questions and answers, or prompts and completions. For simplicity, let's just refer to them as 'PC pairs' moving forward."
OpenAI suggests gathering at least 200 top-notch examples of these 'PC pairs'. Manually putting together this amount of data could take ages, so I enlisted the help of GPT to generate these examples. Here's how I went about it:
Step 1: Convert a book into a TXT file.
Total of 4 books written by Jocko were converted into txt files.
Step 2: chop up the text file into manageable “chunks”
I wrote some Python code to divide the text into segments of roughly 1400 characters, making sure to break at a period so sentences aren't cut in half.
Why 1400 characters? My thinking was that this roughly equates to two or three full paragraphs - probably good length to capture a concept from a book. However, you might prefer different segment lengths, bearing in mind that 8K tokens (each word is around 1.3 tokens) is usually the maximum for GPT-4.
I automated this text segmentation process, which means some chunks may not be ideally divided - they might not begin or conclude at the most logical points. If you're open to investing more time, manually slicing the texts to create training chunks could yield better results.
Here is an example (one of the better ones) of one of these “chunks”
Original Text:
Of the many exceptional leaders we served alongside throughout our military careers, the consistent attribute that made them great was that they took absolute ownership—Extreme Ownership—not just of those things for which they were responsible, but for everything that impacted their mission. These leaders cast no blame. They made no excuses. Instead of complaining about challenges or setbacks, they developed solutions and solved problems. They leveraged assets, relationships, and resources to get the job done. Their own egos took a back seat to the mission and their troops. These leaders truly led.
In the years since we left active duty, we have worked with multitudes of business professionals, from senior executives to frontline managers, across a vast range of industries, including finance, construction, manufacturing, technology, energy, retail, pharmaceutical, health care, and also, military, police, fire departments, and emergency first responders. The most successful men and women we’ve seen in the civilian world practice this same breed of Extreme Ownership. Likewise, the most successful high-performance teams we’ve worked with demonstrate this mind-set throughout their organizations.Step 3: Creating PC pairs
Each of these text chunks are fed into GPT and asked to generate question/answer pairs (which looks like below). I have a code written to automate this process, which I’ll feature in a future article. You could do this manually buy pasting each “chunk” into ChatGPT and asking it to create a prompt-completion pair.
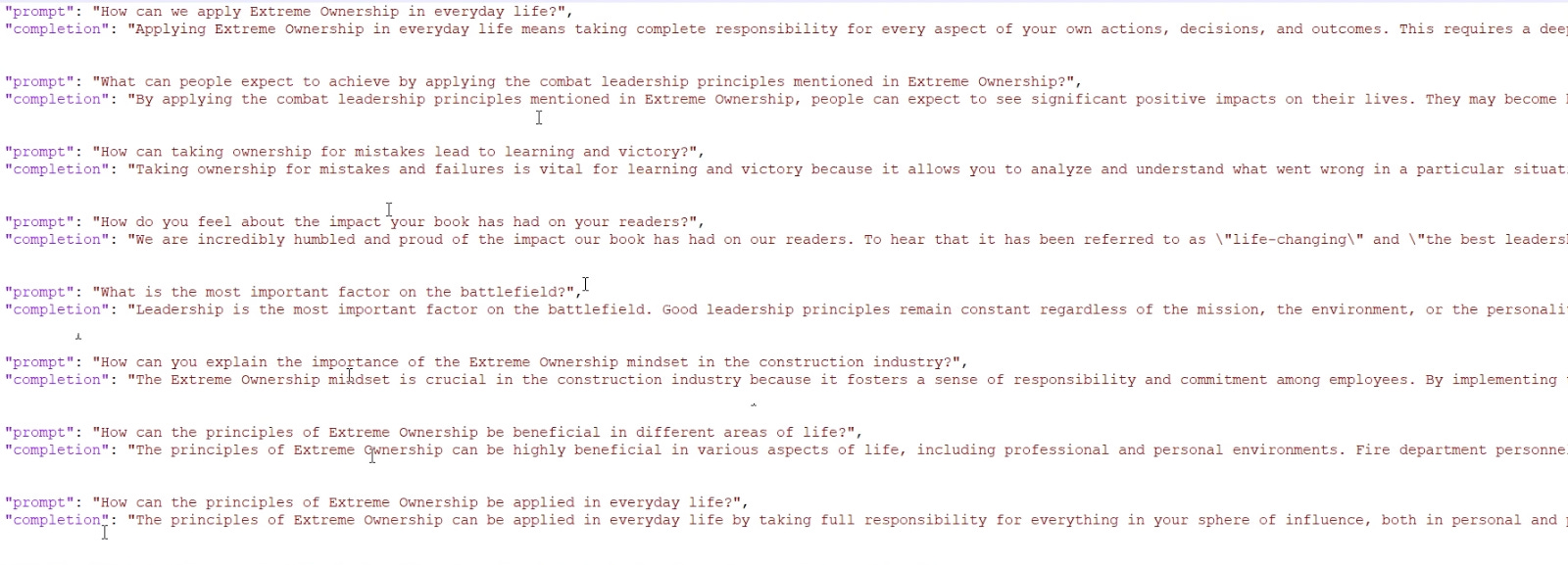
Initially, I tried to use GPT3.5 but could not get the quality I wanted. So I used GPT4 to create these PC pairs which provided higher quality output but took much longer.
BTW, the quality of output did depend on the prompt used.
Here is the prompt I ended up using after a number of trials. I had to tell it to avoid referring to the author and talk like the author (in first person voice) because it had a tendency to speak in 3rd person using phrases like “according to the author…” or “according to the context.. . .”
This is the exact prompt used including the input data (aka “context”):
Given the following context delimited by """", generate a prompt and completion pair in JSON format for finetuning. It is for finetuning a model that would talk like the author. In the prompt, simply ask a question and do not describe the author.
““““Of the many exceptional leaders we served alongside throughout our military careers, the consistent attribute that made them great was that they took absolute ownership—Extreme Ownership—not just of those things for which they were responsible, but for everything that impacted their mission. These leaders cast no blame. They made no excuses. Instead of complaining about challenges or setbacks, they developed solutions and solved problems. They leveraged assets, relationships, and resources to get the job done. Their own egos took a back seat to the mission and their troops. These leaders truly led.
In the years since we left active duty, we have worked with multitudes of business professionals, from senior executives to frontline managers, across a vast range of industries, including finance, construction, manufacturing, technology, energy, retail, pharmaceutical, health care, and also, military, police, fire departments, and emergency first responders. The most successful men and women we’ve seen in the civilian world practice this same breed of Extreme Ownership. Likewise, the most successful high-performance teams we’ve worked with demonstrate this mind-set throughout their organizations.””””And this is what output back from GPT4 could look like:
Prompt/Completion:
{
"prompt": "How can leaders take Extreme Ownership in their professional roles?",
"completion": "Leaders can take Extreme Ownership in their professional roles by recognizing that they are responsible not just for the tasks and objectives they directly oversee, but also for everything that impacts the mission of their organization. This means they should cast no blame and make no excuses, but instead focus on developing solutions and solving problems. They should leverage their assets, relationships, and resources to get the job done, and should be willing to put their own egos aside for the benefit of the mission and their team members. By adopting this mindset, they can lead by example and foster a culture of Extreme Ownership throughout their organization, ultimately resulting in increased success and performance across the team."
}
From my observations, GPT-4 showcased a significant improvement over GPT-3.5 in grasping and expressing the main idea of the “context”. While GPT-3.5 performed well, GPT-4 delivered a more consistent performance in terms of not returning weird results.
By the way, when I refer to 'context' here, I'm talking about the same 1400-character “chunks” of text I mentioned earlier. The term 'context' is just a more precise way of referring to it in the realm of AI.
So, to recap, these are the steps so far: converting ebooks into text files, slicing the text into 1400 character “chunks”, and subsequently transforming each chunk into a PC pair tailored for fine-tuning.
Altogether, the four books yielded around 1500 PC pairs. The cost of generating these 1500 pairs using GPT-4 was approximately $25 in tokens.
Each pair exists as its individual JSON object in a list. So, you’d need to consolidate them into a single JSONL file.
Step 4: Fine-tuning and creating your own custom model
Next, I utilized the OpenAI command line tool to generate a fine-tuned model, based on the OpenAI Davinci model. (Note, you'll need an API key to run the command line tool because the fine-tuning isn't carried out in ChatGPT.)
The command you'll run looks like this:
openai -k <API KEY> api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m davinciThe model you've just created resides on the OpenAI server (you don't receive any file in return). What you do get is an identifier, which you can use as a reference in your app.
The fine-tuning process took approximately 40 minutes for the 1500 PC pairs, costing around $25.
Step 5: Using the new custom model “ChatJocko”
The last stage involves leveraging this freshly minted 'ChatJocko.'
I do this by scripting code to prompt OpenAI using the name of the new model.
Since this is a GPT-3 model, you can't use the ChatGPT API. Instead, you'll need to resort to the older API. Here's a snippet of Python code you can use as a guide to query your custom model.
response = openai.Completion.create(
engine="<your custom model identifier here>",
prompt=prompt,
temperature=0.8,
max_tokens=400,
top_p=1.0,
n=1,
best_of=1,
frequency_penalty=0.9,
presence_penalty=0.7,
)And here is an example of what I get from the ChatJocko:
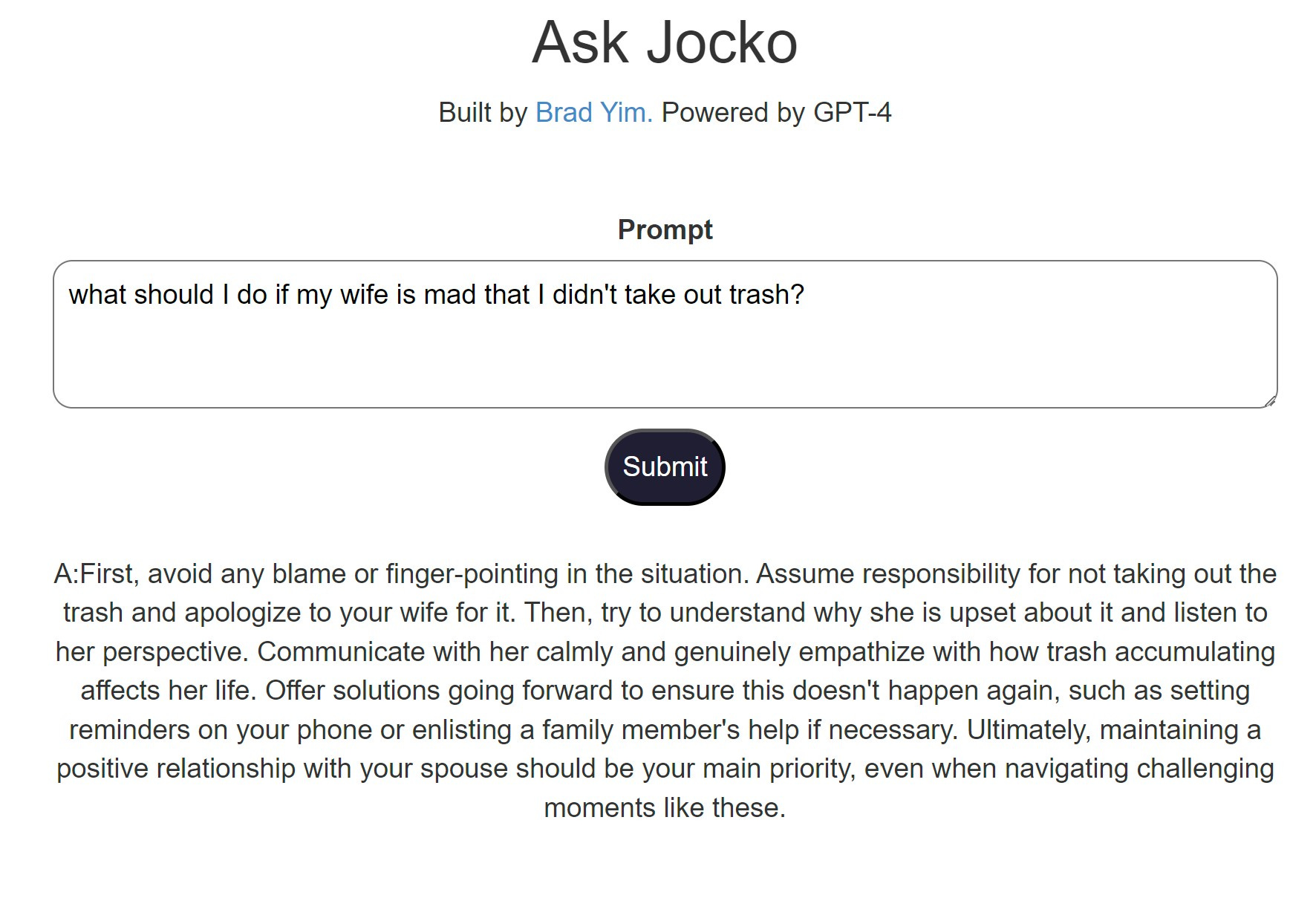
Concluding thoughts:
When you interact with ChatJocko, this is likely what's happening:
If you pose a question that closely mirrors one found in your prompt/completion pairs, you can expect a response that aligns closely with content from one of Jocko's books.
If your question is entirely unrelated to your training data, the bot will default to the 'base' model (which for most people you’d want to use Davinci GPT 3.0. As of now, fine-tuning isn't widely accessible for GPT 3.5 and 4.0) and the answer will draw from GPT’s general knowledge. However, the style, voice and tone of the response will closely mirror what’s found in Jocko’s books.
The key to success lies in assembling quality training data. It's not sufficient to simply toss a heap of text into the training process and expect a top-notch custom model. As you’ve seen here, this requires a significant amount of human discretion.
I only checked a handful of the 1500 PC pairs since I was building this as an experiment. If I had to check all the pairs it probably would’ve taken me a whole week.
The answers I’ve been getting are okay, but I think the current bot can be significantly improved with more training data.
I will not be releasing ChatJocko to the public because it’s trained on copyrighted materials. But you can imagine what bots you could build for your own personal use by learning how to “fine-tune” GPT. I hope you see that it’s easier that you thought.
Subscribe to stay updated on the latest happenings in the AI world. In my newsletter, I’ll try out the latest AI tools and tell you how they work.
The world is changing rapidly, and remaining passive at this juncture could spell disaster for your career. Now is the time to become even more aggressive. Lean forward and charge ahead. Let's get after it!
-Brad